9
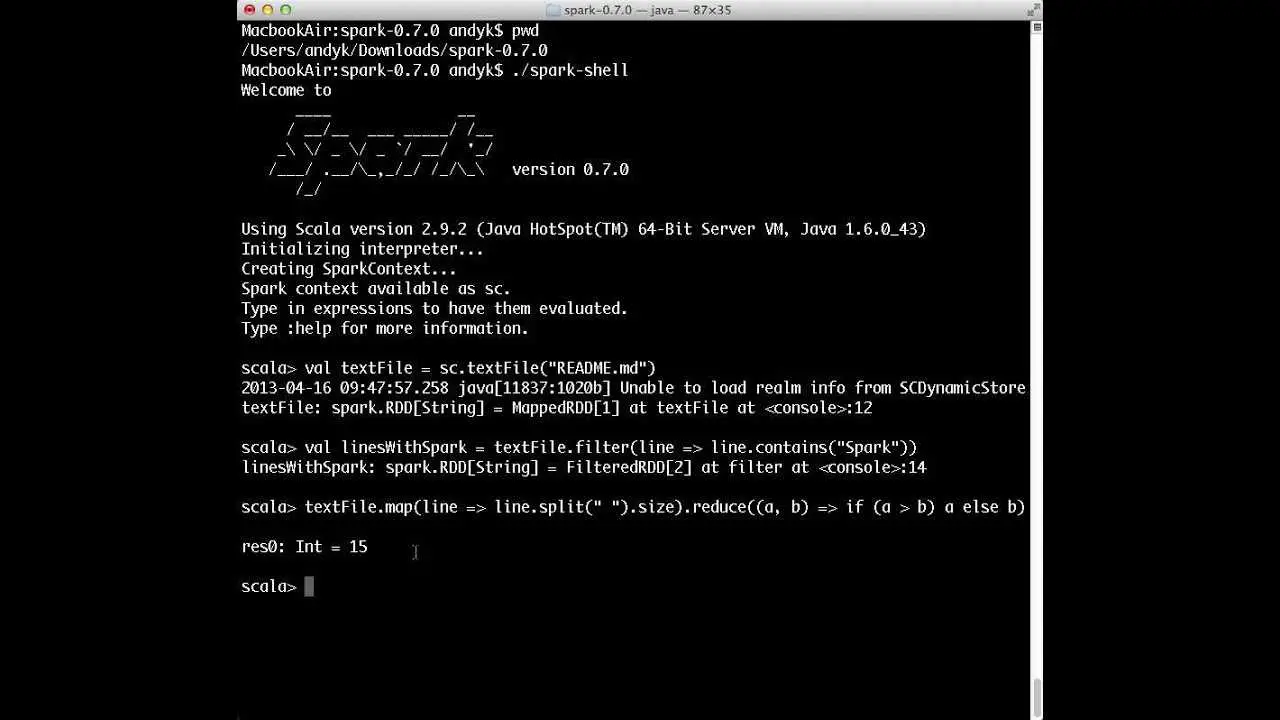
O Apache Spark ™ é um mecanismo rápido e geral para processamento de dados em larga escala.Velocidade Execute programas até 100x mais rápido que o Hadoop MapReduce na memória ou 10x mais rápido no disco.O Spark possui um mecanismo de execução avançado do DAG que suporta fluxo de dados cíclicos e computação na memória.
Local na rede Internet:
http://spark.apache.orgCategorias
Alternativas ao Apache Spark para Linux
18
Apache Hadoop
O Apache Hadoop é uma estrutura de software de código aberto que suporta aplicativos distribuídos com muitos dados licenciados sob a licença Apache v2.
1
Disco MapReduce
O Disco é uma estrutura leve e de código aberto para computação distribuída com base no paradigma MapReduce e escrito em Python.