0
OCR Text Detection Tool
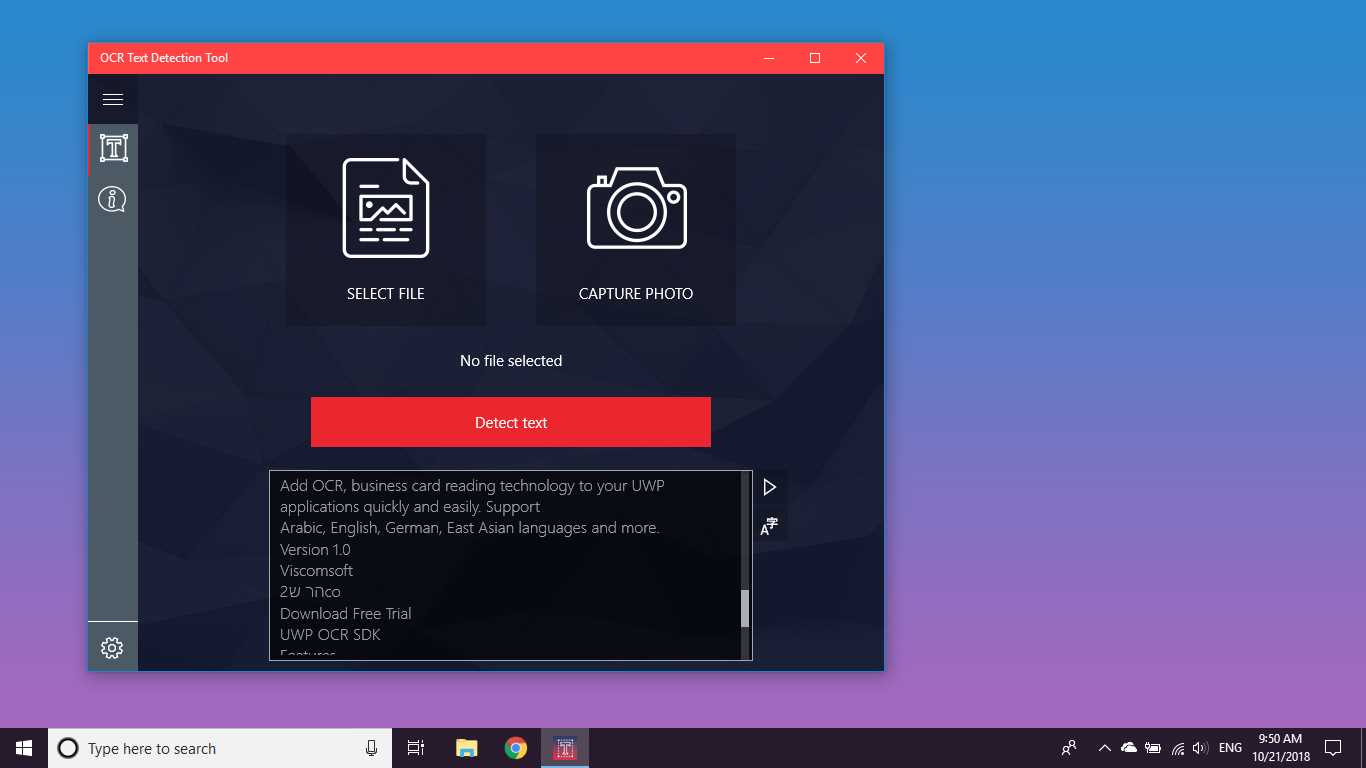
Fornece detecção de texto rápida e precisa de qualquer arquivo de imagem baixado do seu dispositivo ou tirado com um instantâneo.Ele também suporta detecção de texto em PDF e detecção de manuscrito baseado em texto e tradução de texto em 114 idiomas diferentes.
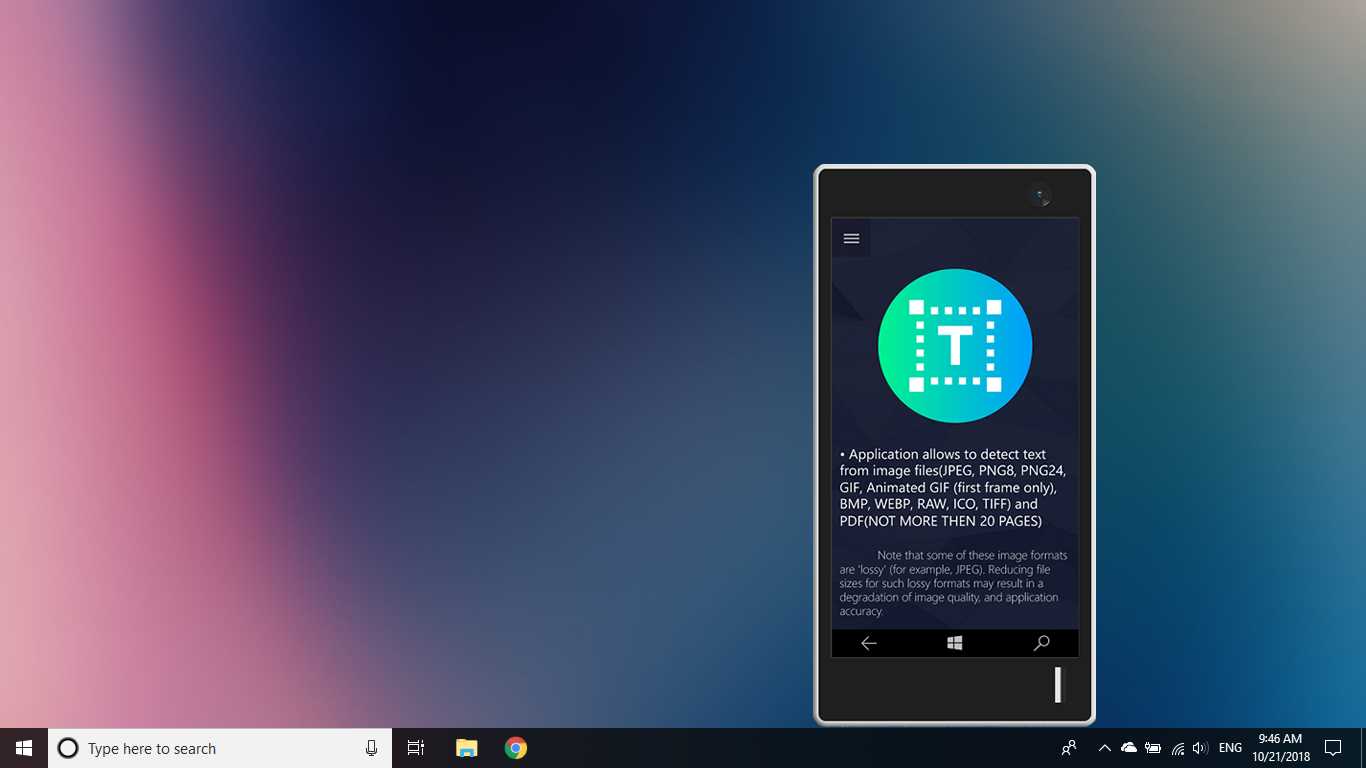
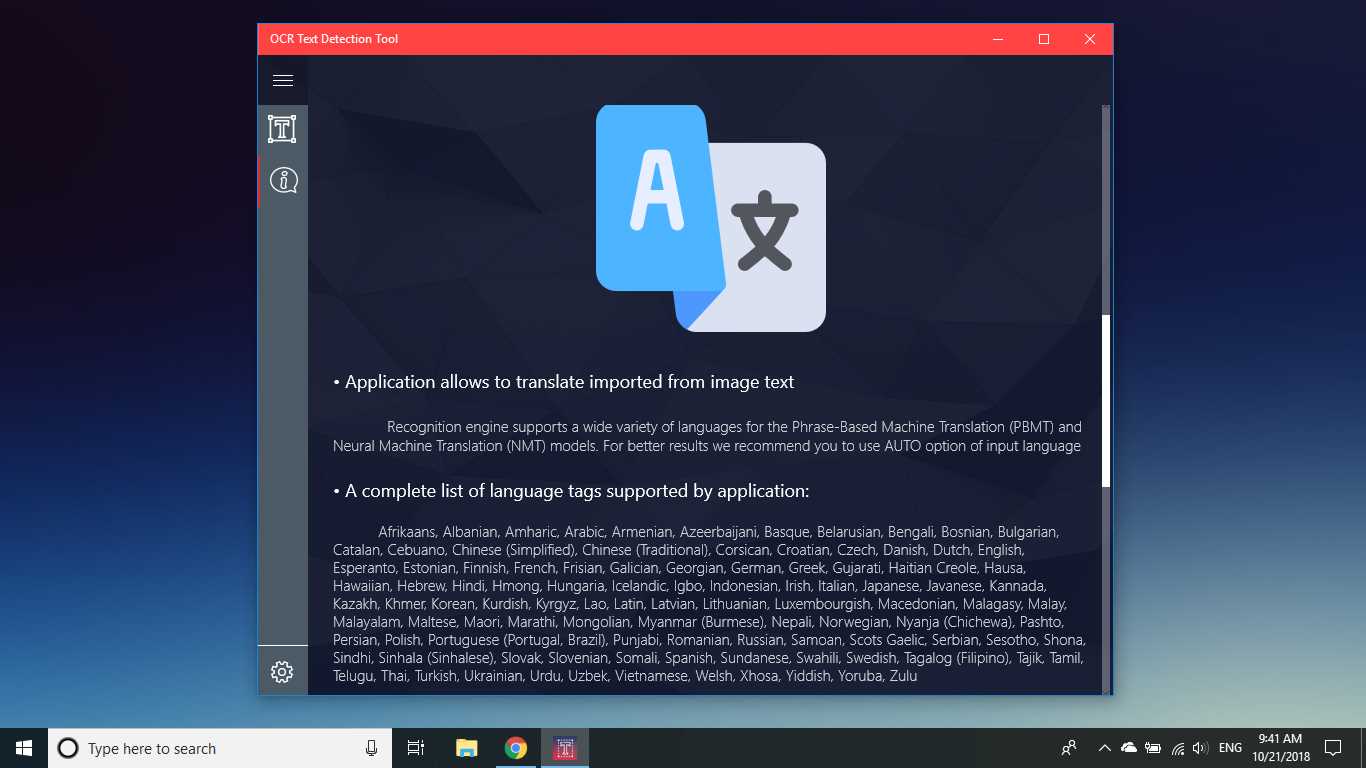
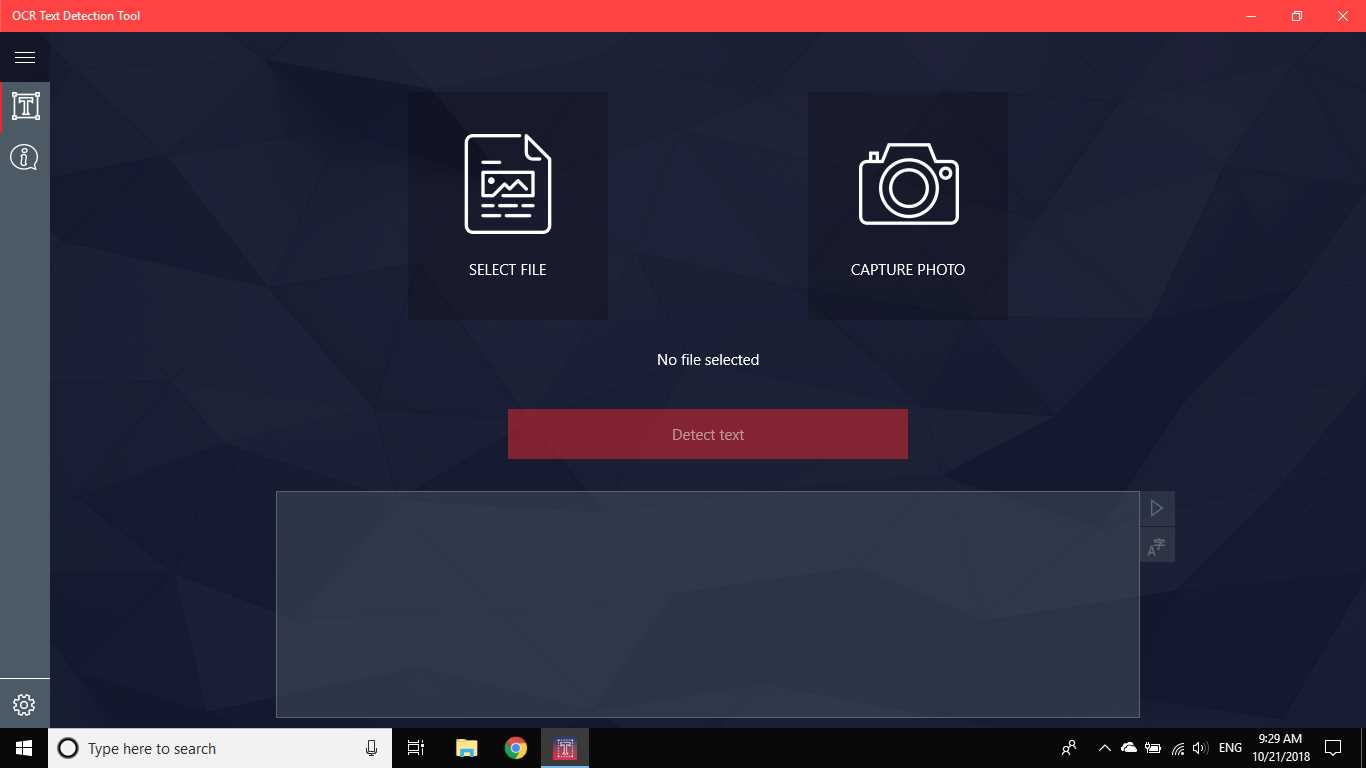
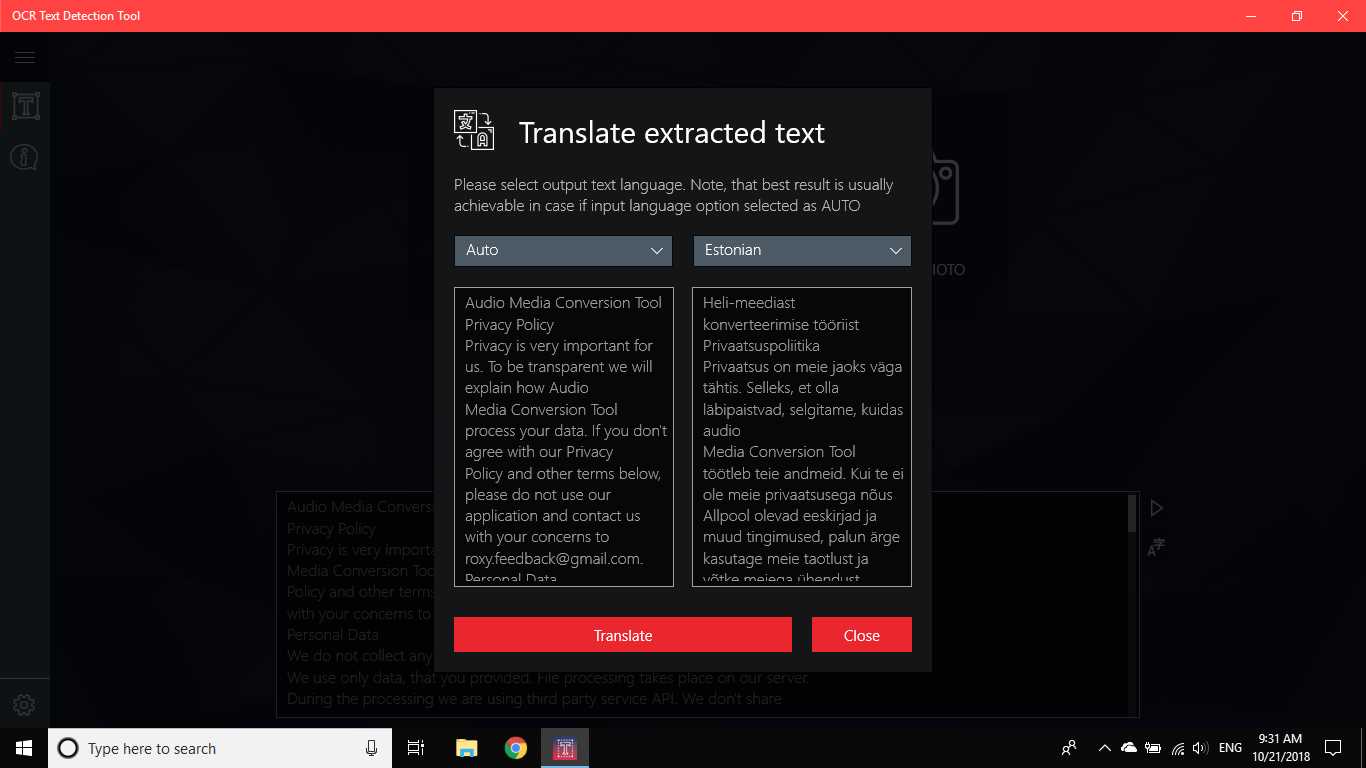
A Ferramenta de detecção de texto OCR fornece detecção de texto precisa e rápida de qualquer arquivo de imagem baixado do seu dispositivo ou tirado com um instantâneo.Ele também suporta a detecção de texto de um documento PDF (atualmente não mais de 20 páginas, mas estamos trabalhando para expandir a funcionalidade).O aplicativo também suporta detecção de escrita manual e tradução de texto em 114 idiomas diferentes.O design amigável, claro e conveniente torna o trabalho com o aplicativo fácil e compreensível.* Formatos disponíveis: JPEG, PNG8, PNG24, GIF, GIF animado (somente primeiro quadro), BMP, WEBP, RAW, ICO, TIFF, PDF (atualmente não mais de 20 páginas, mas estamos trabalhando para expandir a funcionalidade)o recurso de reconhecimento é capaz de detectar uma ampla variedade de idiomas e pode detectar vários idiomas em uma única imagem: africâner (af), árabe (ar), assamês (as), azerbaijano (az), bielorrusso (be), bengali (bn), Búlgaro (bg), catalão (ca), chinês (zh *), croata (hr), tcheco (cs), dinamarquês (da), holandês (nl), inglês (en), estoniano (et), filipino (filou tl), finlandês (fi), francês (fr), alemão (de), grego (el), hebraico (he ou iw), hindi (oi), húngaro (hu), islandês (is), indonésio (id), Italiano (it), japonês (ja), cazaque (kk), coreano (ko), quirguiz (ky), letão (lv), lituano (lt), macedônio (mk), marata (m), mongol (mn), Nepalês (ne), norueguês (no), pashtu (ps), persa (fa), polonês (pl), português (pt), romeno (ro), russo (ru), sânscrito (sa), sérvio (sr), Eslovaco (sk), esloveno (sl), espanhol (es), sueco (sv), tâmil (ta), tailandês (th), turco (tr), ucraniano (uk), urdu (ur), uzbeque (uz), vietnamita (vi) Confira, você não tem nada a perder!
Local na rede Internet:
https://www.microsoft.com/store/apps/9PL1PPFPT8VJCategorias
Alternativas ao OCR Text Detection Tool para Linux
71
35
GImageReader
O gImageReader é um front-end simples do Gtk / Qt para o Tesseract OCR Engine.Features: - Importe documentos e imagens em PDF do disco, dispositivos de digitalização, área de transferência e capturas de tela
9
8
6
5
5
4