0
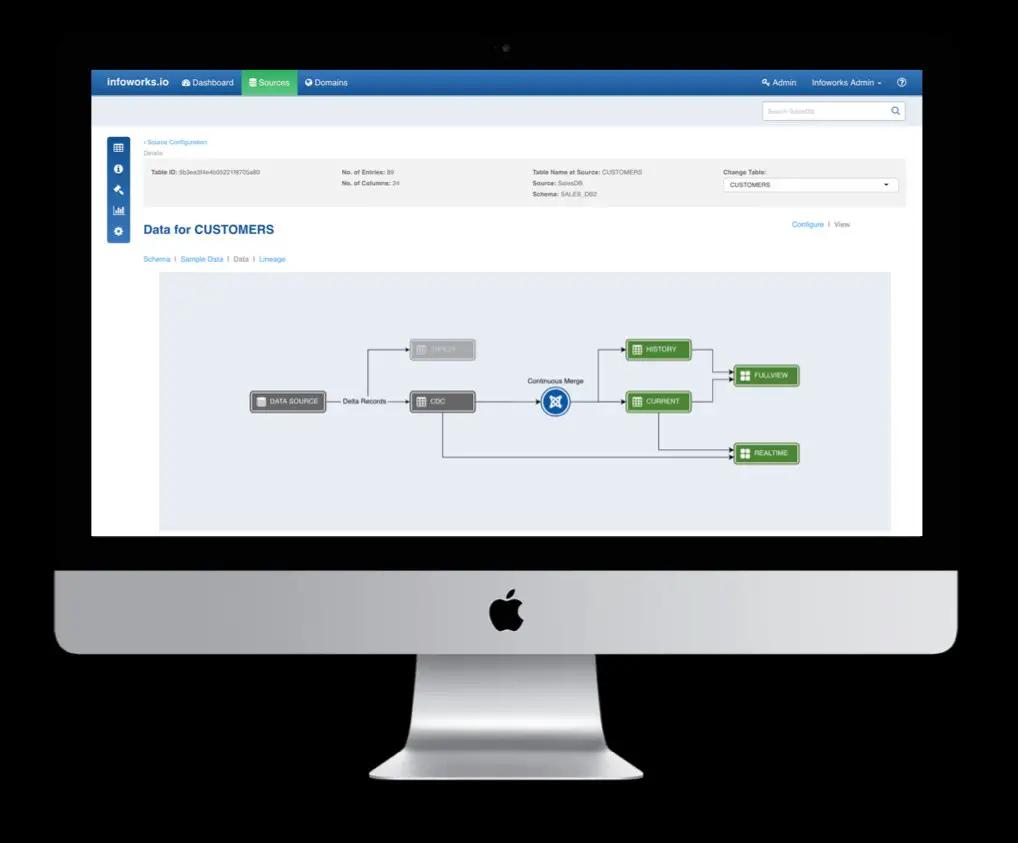
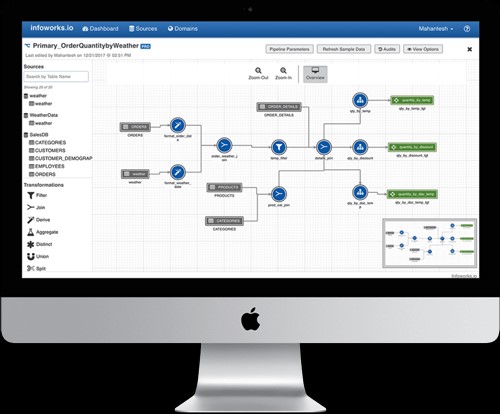
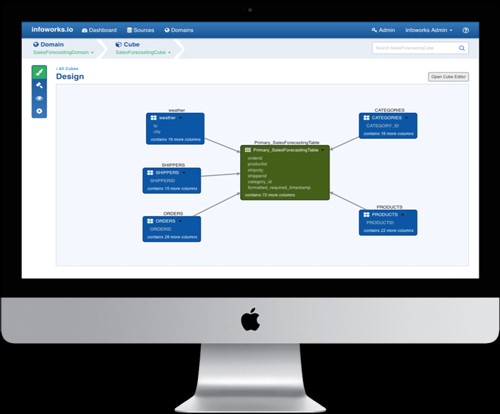
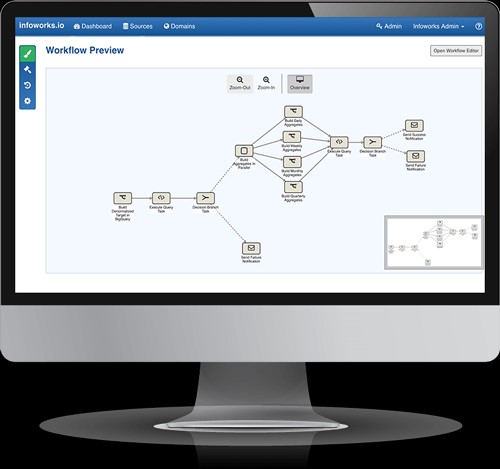
Existem muitas ferramentas de codificação visual que podem ajudá-lo em sua jornada de big data e nuvem.O problema?As ferramentas pontuais não automatizam todo o processo de engenharia de dados ... A diferença da Infoworks?A automação de ponta a ponta é a chave da nossa plataforma de engenharia de dados ágil O Infoworks Autonomous Data Engine automatiza a engenharia de dados e os dataops para processos de fluxo de trabalho de big data de ponta a ponta, desde a ingestão até o consumo.Nossos clientes implementam a produção em dias usando 5x menos horas de engenharia.Automação de ingestão de dados A Infoworks fornece um ambiente sem código para configurar a ingestão de dados (lote, streaming, captura de dados alterados) de uma ampla variedade de fontes de dados.Quando possível, usamos conectores nativos para fornecer a maior velocidade possível de ingestão de dados e ingerir dados de origem em um processo paralelo de alto desempenho, preservando automaticamente a precisão dos dados.Sincronização automatizada de metadados Nossa plataforma ágil de engenharia de dados rastreia automaticamente as fontes de dados, incluindo arquivos simples, XML, JSON e bancos de dados relacionais.A solução aprende os metadados e infere relacionamentos de dados para os dados ingeridos de fontes de dados externas, bem como para conjuntos de dados criados usando o Infoworks, tornando os metadados pesquisáveis por meio de um repositório de metadados.Sincronização automatizada de dados Os dados de origem são sincronizados continuamente com os dados no seu data lake usando métodos baseados em log e em consultas para captura de dados alterados.O Infoworks lida automaticamente com alterações lentas dos dados e do esquema e suporta o modo de streaming, lote e incremental de sincronização e exportação de dados.Saiba mais sobre nossos recursos visitando nosso site ou agendando uma demonstração.
Local na rede Internet:
https://www.infoworks.io/product/Categorias